
코딜기
[Python/ML] 로지스틱 회귀 모델 Logistic Regression 본문
ML & DL Process/Build & Train Model
[Python/ML] 로지스틱 회귀 모델 Logistic Regression
코딜기 2022. 3. 1. 22:59반응형
로지스틱 회귀(Logistic Regression)란 무엇일까요?
- 분류 데이터에 선형 회귀모형을 적용시켰을 경우 종속변수의 특성이 무시당하는 경우가 생기기도 합니다.
- 이를 해결하기 위해 예측 확률을 종속변수의 값 증감에 따라 함께 증감하고, 0과 1 사이의 값을 갖는 확률로 변환하여 변수의 특성을 고려해줍니다.

- 로지스틱 회귀 모델은 Odds라는 상대적인 비율 개념을 이용해 선형 회귀 모델을 변형시킨 모델입니다.
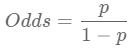
- Odds 식에 자연로그 ln을 씌워 기존의 회귀식에서 Y위치에 치환해줍니다. 아를 로짓 변환이라고 합니다.
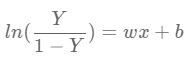
- 위 식을 Y에 대해 정리하면 시그모이드 함수(Sigmoid Function)가 됩니다.
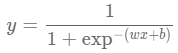
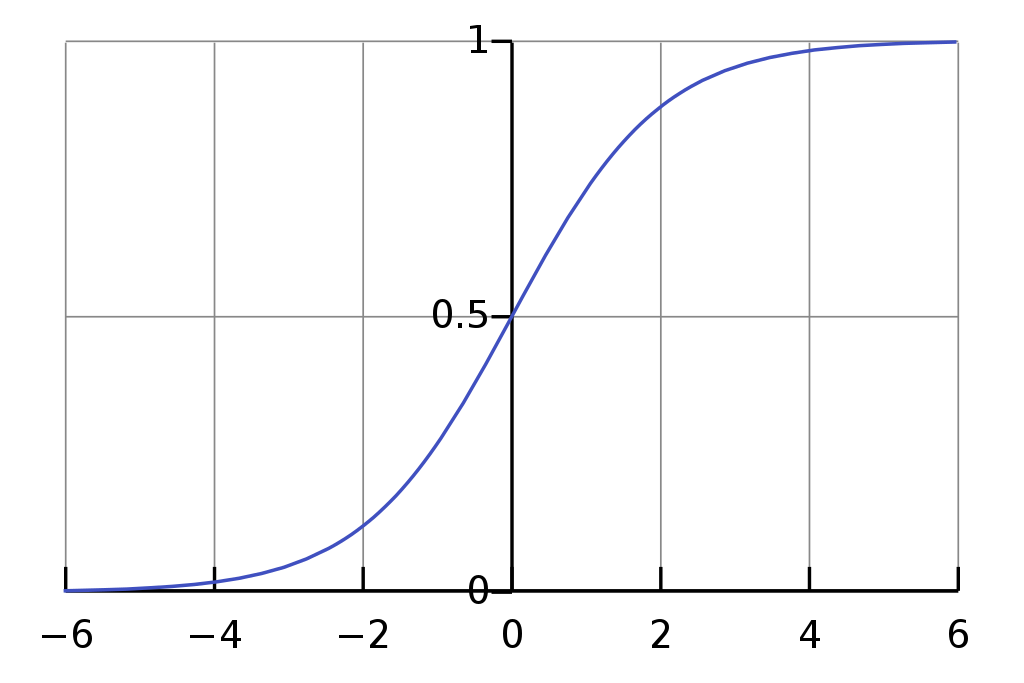
- 시그모이드 함수 : S자 또는 시그모이드 곡선을 갖는 수학 함수
- 로지스틱 회귀모형 : 시그모이드 함수의 하나의 예시로 로짓 변환을 이용하여 선형 회귀모형을 S자형으로 변형시킨 모델
Logistic Regression의 대표적인 파라미터
- C (float) : 얼마나 모델에 규제를 넣을지 결정하는 값 (값이 작을수록 모델에 규제가 높아진다.)
- fit_intercept (bool) : 회귀 수식에서 y절편을 포함할지의 유무
- random_state (int) : 내부적으로 사용되는 난수 값
- class_weight (dict) : 학습 시 클래스의 비율에 맞춰 손실 값에 가중치 부여
Python을 통한 모델 적용
- 기본 파라미터 설정으로 진행한 Logistic Regression 분석
from sklearn.linear_model import LogisticRegression
# LogisticRegression 모델 선언 후 Fitting
lr = LogisticRegression()
lr.fit(x_train, y_train)
# Fitting된 모델로 x_valid를 통해 예측을 진행
# 0 or 1로된 레이블 예측을 할 때
y_pred = lr.predict(x_valid)
# 0 ~ 1 사이의 확률값 예측을 할 때
y_pred_proba = lr.predict_proba(x_valid)y_pred 혹은 y_pred_proba를 통한 모델 성능 검증은 다른 포스팅에 정리하겠습니다.
- 각 변수들의 계수와 모델의 절편 값을 확인하고 싶을 때
# 변수의 계수를 확인하는 코드
lr.coef_
# 절편값을 확인하는 코드
lr.intercept_변수들의 계수를 확인함으로써 어떤 변수에 얼마만큼의 가중치가 할당되는지 확인할 수 있습니다.
결과로 나오는 계수의 순서는 컬럼의 순서대로 적용시켜 읽으면 됩니다.
로지스틱 회귀분석을 하기 전에는 반드시 데이터 스케일링 과정이 꼭 필요합니다.
- 로지스틱 회귀분석은 Regularization을 사용하기 때문에 데이터 스케일링 과정이 꼭 필요합니다.
- 로지스틱 회귀분석을 할 때는 거의 Standard Scaling을 통해 스케일링을 진행합니다.
반응형
'ML & DL Process > Build & Train Model' 카테고리의 다른 글
| [Python/ML] 이진 분류(Binary Classification) (0) | 2022.03.11 |
|---|---|
| [Python/ML] XGBoost 모델 Boosting Ensemble (0) | 2022.03.11 |
| [Python/ML] 랜덤 포레스트(Random Forest) Bagging Ensemble (0) | 2022.03.07 |
| [Python/ML] 의사결정 나무 (Decision Tree) (2) | 2022.03.07 |
| [Python/ML] 서포트 벡터 머신 (Support Vector Machine) SVM (0) | 2022.03.04 |
'ML & DL Process/Build & Train Model' Related Articles
more



Comments