
코딜기
[Python/ML] 의사결정 나무 (Decision Tree) 본문
반응형
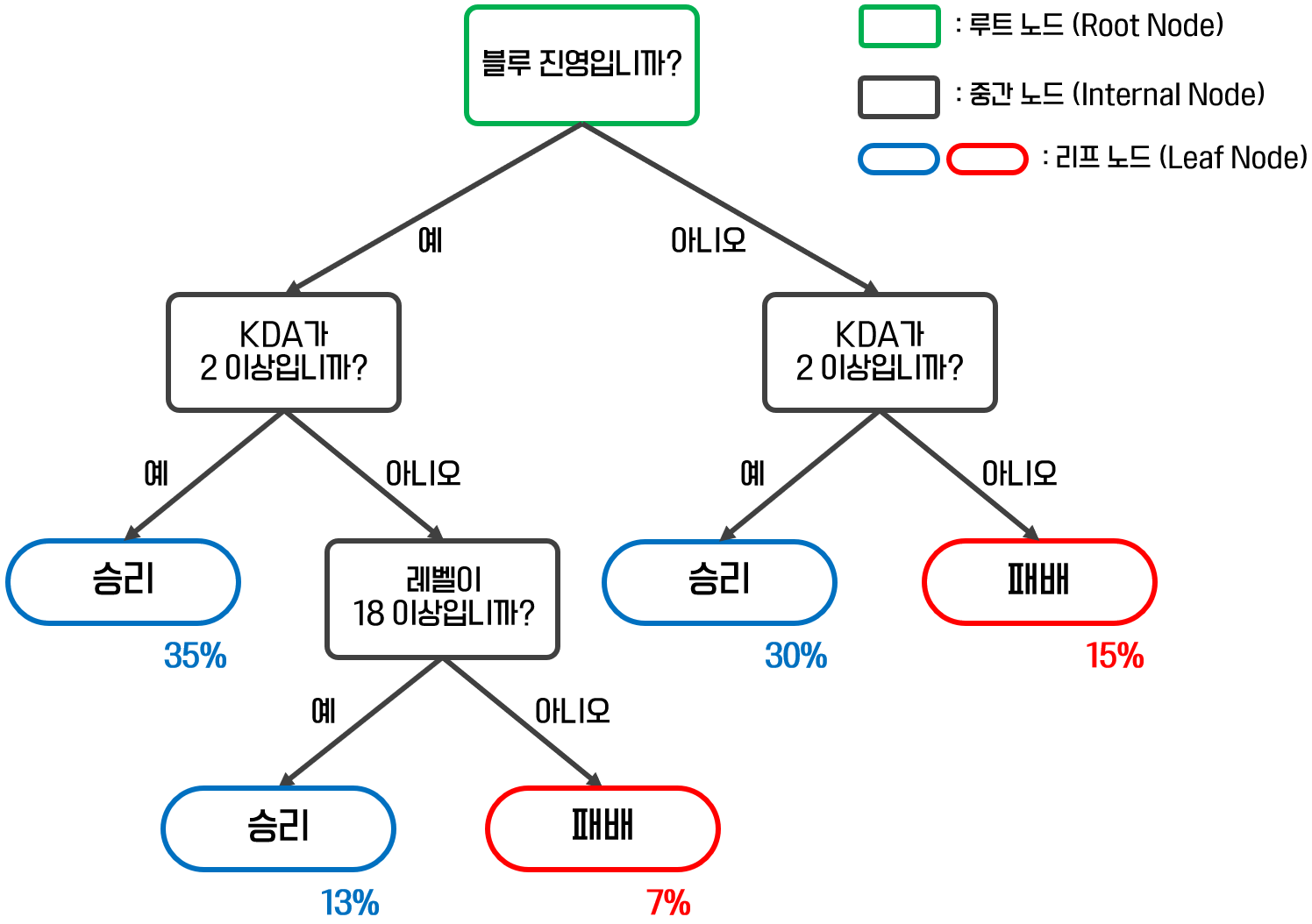
의사결정 나무(Decision Tree)란 무엇일까요?
- 의사결정 나무(Decision Tree)는 분류, 회귀 문제에 모두 사용할 수 있는 강력한 모델입니다.
- 의사결정 나무는 입력 변수를 특정한 기준으로 분기해 트리 형태의 구조로 분류하는 모델입니다.
불순도 (Impurity, Entropy)
- 불순도란 정보 이론에서 말하는 얻을 수 있는 정보량의 정도를 뜻하고, 이는 분기된 하나의 범주안에 서로 다른 데이터가 얼마나 섞여있는지를 의미합니다.
- 하나의 범주에 여러 종류의 데이터가 속해있으면 불순도는 높아집니다.
- 데이터를 분기할 때 현재 노드보다 자식 노드의 불순도가 감소되도록 분기해야 합니다.
- 불순도를 수치적으로 나타낼 수 있는 함수가 불순도 함수이고, 지니계수와 엔트로피 계수가 있습니다.
1. 지니 계수 (Gini Index)
- 지니 계수는 각 마디에서의 불순도 또는 다양도를 재는 척도 중 하나입니다.
- 0(하나의 클래스로만 구성된 상태)에서 1/c(가장 혼합도가 높은 상태의 값)의 범위를 갖습니다.
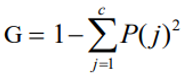
c : 범주 수
P : 데이터가 목표 변수의 j번째 범주에 속할 확률
2. 엔트로피 계수 (Entropy Index)
- 엔트로피 계수는 bit 개념을 이용해 불순도를 측정하는 척도입니다.
- 0(하나의 클래스로만 구성된 상태)에서 1(가장 혼합도가 높은 상태의 값)의 범위를 갖습니다.
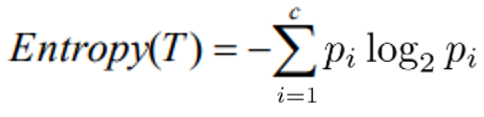
c : 범주 수
P : 데이터가 목표 변수의 j번째 범주에 속할 확률
가치 치기 (Pruning)
- 풀 트리를 생성하게 되면 모델이 과적합(Overfitting)이 되는데 이를 방지하기 위해 불필요한 가지들을 제거합니다.
- 트리의 깊이를 제한하거나, 리프 노드의 데이터 개수를 제한하는 방식으로 가지치기를 진행할 수 있습니다.
Greedy한 특징
- 의사결정 나무는 한번 분기하면 이루에 최적의 트리 형태가 발견되더라도 되돌아갈 수 없는 특징을 가지고 있습니다.
- 따라서 최적의 트리 생성을 보장하지 않습니다.
의사결정 나무의 알고리즘
- 의사결정 나무의 분류 모델은 불순도를 최소화(=정보량의 최대화)하는 방향으로 분기를 진행합니다.
- 분리 기준으로 지니 계수 / 엔트로피 계수 / 카이제곱 통계량의 P-value가 있습니다.
- 의사결정 나무의 회귀 모델은 분산을 최대로 감소시키는 방향으로 분기를 진행합니다.
- 분리 기준으로 F 통계량의 P-value / 분산 감소량이 있습니다.
- 의사결정 나무의 알고리즘은 크게 CART / C4.5 / CHAID가 있습니다.
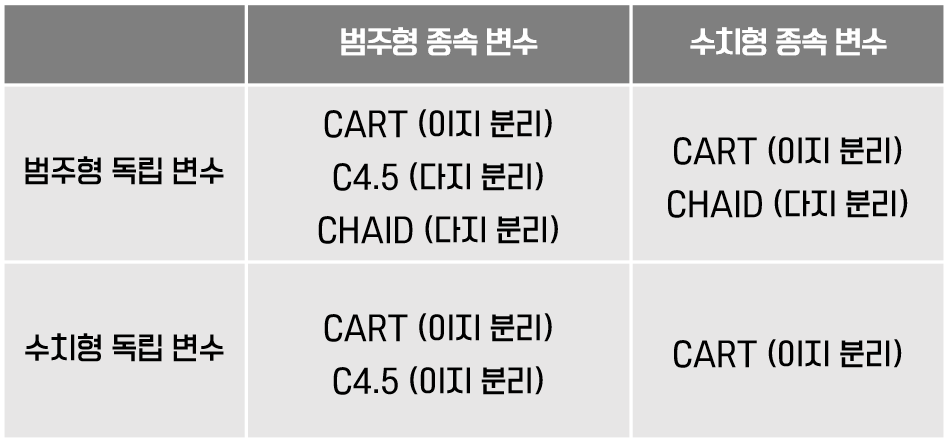
- 종속 변수가 수치형일때 C4.5를 사용하고 싶다면 종속 변수의 값을 범주화시킨 후 적용시키면 됩니다.
- 독립 변수가 수치형일때 CHAID를 사용하고 싶다면 독립 변수의 값을 범주화시킨 후 적용시키면 됩니다.
1. CART (Classification and Regression Trees)
- 분류 모델에서는 지니 계수를 가장 많이 감소시켜주는 변수(영향을 많이 끼치는 변수)를 찾아 분리를 합니다.
- 회귀 모델에서는 노드별로 값의 평균을 구하고, 분산을 가장 많이 감소시켜주는 변수를 찾아 분리를 합니다.
- CART는 이지 분리를 합니다.
2. C4.5
- 분류 모델에서 쓰이며 엔트로피 계수를 가장 많이 감소시켜주는 변수(영향을 많이 끼치는 변수)를 찾아 분리를 합니다.
- 독립 변수가 수치형이면 범위로 그룹화가 되고, 그룹별 엔트로피 계수를 계산해 이지 분리가 이루어집니다.
- 독립 변수가 범주형이면 모든 범주들에 대해 분기가 되는 다지 분리가 이루어집니다. (범주의 개수와 리프 노드의 개수가 동일하게 분기됩니다.)
3. CHAID (Chi-Squared Automatic Interaction Detection)
- 분류 모델에서는 Pearson의 카이제곱 통계량을 이용하여 분리를 합니다.
- 카이제곱 통계량 값이 크면 P-value는 작아지게 되고, P-value가 가장 작은 변수를 찾아 분리를 합니다.
- 회귀 모델에서는 두 개 이상의 그룹에 대해 평균의 차이를 검정하는 분산 분석표(ANOVA)의 F 통계량을 이용하여 분리를 합니다.
- F 통계량 값이 크면 P-value는 작아지게 되고, P-value가 가장 작은 변수를 찾아 분리를 합니다.
- CHAID는 이지 분리, 다지 분리 모두 가능합니다.
Decision Tree의 대표적인 파라미터
- crierion (str) : 정보량 계산 시 사용할 수식 (gini / entropy)
- max_depth (int) : 생성할 트리의 높이
- min_samples_split (int) : 분기를 수행하는 최소한의 데이터 수
- max_leaf_nodes (int) : 리프 노드가 가지고 있을 수 있는 최대 데이터 수
- random_state (int) : 내부적으로 사용되는 난수 값
Python을 통한 모델 적용
- 기본 파라미터 설정으로 진행한 Decision Tree 분류 모델
from sklearn.tree import DecisionTreeClassifier
# DecisionTreeClassifier 모델 선언 후 Fitting
dtc = DecisionTreeClassifier()
dtc.fit(x_train, y_train)
# Fitting된 모델로 x_valid를 통해 예측을 진행
y_pred = dtc.predict(x_valid)- 기본 파라미터 설정으로 진행한 Decision Tree 회귀 모델
from sklearn.tree import DecisionTreeRegressor
# DecisionTreeRegressor 모델 선언 후 Fitting
dtr = DecisionTreeRegressor()
dtr.fit(x_train, y_train)
# Fitting된 모델로 x_valid를 통해 예측을 진행
y_pred = dtr.predict(x_valid)- 트리를 분기하는 과정에서의 Feature Importance를 알고 싶을 때
feature_importance = pd.DataFrame(dtc.feature_importances_.reshape((1, -1)), columns=x_train.columns, index=['feature_importance'])
feature_importance의사결정 나무의 불연속성과 불안정성
- 연속형 변수를 불연속적인 값으로 취급하기 때문에 회귀 모델에서는 많이 쓰이지 않습니다.
- Train Data에만 의존하기 때문에 새로운 데이터의 예측에서는 불안정성을 보이기 때문에 가지치기 혹은 Cross Validation을 통해 안정성을 얻습니다.
반응형
'ML & DL > Build & Train Model' 카테고리의 다른 글
| [Python/ML] 이진 분류(Binary Classification) (0) | 2022.03.11 |
|---|---|
| [Python/ML] XGBoost 모델 Boosting Ensemble (0) | 2022.03.11 |
| [Python/ML] 랜덤 포레스트(Random Forest) Bagging Ensemble (0) | 2022.03.07 |
| [Python/ML] 서포트 벡터 머신 (Support Vector Machine) SVM (0) | 2022.03.04 |
| [Python/ML] 로지스틱 회귀 모델 Logistic Regression (0) | 2022.03.01 |
'ML & DL/Build & Train Model' Related Articles
more



Comments