
코딜기
[Python/ML] 스케일링(Scaling) Min-Max Scaling / Standard Scaling 본문
ML & DL/Data Preprocessing
[Python/ML] 스케일링(Scaling) Min-Max Scaling / Standard Scaling
코딜기 2022. 2. 24. 23:22반응형
데이터 전처리 과정에서 스케일링은 왜 해야 할까요??
- 수치형 변수의 크기(단위)가 변수마다 다르다면 종속 변수에 미치는 영향력이 제대로 표현되지 않을 수 있습니다.
- 이를 해결하기 위해 모든 변수의 범위를 조절해주는 과정이 스케일링입니다.
- 스케일링은 분포의 모양을 바꿔주진 않습니다.
- Scikit-learn에서는 여러 종류의 스케일링 함수를 제공하고 있지만 가장 많이 쓰이는 Min-Max Scaling과 Standard Scaling을 다뤄보겠습니다.
Min-Max Scaling
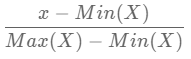
- 변수의 범위를 바꿔주는 정규화 스케일링 기법입니다. (기본값은 0~1입니다.)
- 이상 값 존재에 민감합니다.
- 분류 모델보다 회귀 모델에 적합합니다.
- 보통 이미지쪽에서 쓰입니다.
- Scaling은 값을 조정하는 과정이기 때문에 수치형 변수에만 적용됩니다.
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler 선언 및 Fitting
mMscaler = MinMaxScaler()
mMscaler.fit(numeric_data)
# 데이터 변환
mMscaled_data = mMscaler.transform(numeric_data)
# 데이터 프레임으로 저장
mMscaled_data = pd.DataFrame(mMscaled_data)Standard Scaling

- 데이터를 표준 정규 분포화 시키는 z-score 정규화입니다.
- 변수의 평균을 0으로, 표준 편차를 1로 만들어 주는 표준화 스케일링 기법입니다.
- 이상 값 존재에 민감합니다.
- 회귀 모델보다 분류 모델에 적합합니다.
- Scaling 은 값을 조정하는 과정이기 때문에 수치형 변수에만 적용됩니다.
from sklearn.preprocessing import StandardScaler
# StandardScaler 선언 및 Fitting
sdscaler = StandardScaler()
sdscaler.fit(numeric_data)
# 데이터 변환
sdscaled_data = sdscaler.transform(numeric_data)
# 데이터 프레임으로 저장
sdscaled_data = pd.DataFrame(sdscaled_data)
Scaling 과정을 마친 후에는 항상 데이터의 describe를 확인하는 습관이 필요합니다.
- Min-Max Scaling은 최댓값이 1이고, 최솟값이 0인지 확인해야 합니다.
- Standard Scaling은 평균이 1이고, 표준 편차가 0인지 확인해야 합니다.
Train Data에 Valid / Test Data의 정보가 들어가면 안됩니다.
- Scaling을 할 때 항상 Fit은 Train Data에만 해야 합니다.
- Train Data로부터 학습된 [mean]값과 [variance]값을 Valid / Test Data에 적용하기 위함입니다.
반응형
'ML & DL > Data Preprocessing' 카테고리의 다른 글
'ML & DL/Data Preprocessing' Related Articles
more



Comments