
코딜기
[Python/ML] 머신러닝 데이터 셋 나누기 train_test_split/reset_index 본문
ML & DL/Data Preprocessing
[Python/ML] 머신러닝 데이터 셋 나누기 train_test_split/reset_index
코딜기 2022. 3. 2. 00:31반응형
데이터를 왜 train data / valid data / test data로 나눌까요?
- 경진대회에서는 보통 train data와 test data를 기본적으로 나눠서 제공합니다.
- train data로 모델을 학습시키고, 학습된 모델을 통해 제공받은 test data를 예측하여 제출하는 방식으로 진행됩니다.
1. train data와 test data의 쓰임
- 예측이 필요한 데이터를 모델에 적용시키려면 모델을 학습시킬 데이터가 필요한데 이를 train data라고 합니다.
- 학습된 모델을 가지고 예측을 하는데 예측 과정에서 쓰이는 데이터를 test data라고 합니다.
- train data에는 예측해야 하는 변수가 포함되어있지만 test data에는 포함되어있지 않는 것이 특징입니다.
- train data로 모델을 학습시키고, 곧바로 test data를 예측하게 되면 예측값이 과적합(Overfitting)된 값인지 아닌지 알 수 없습니다.
2. train data와 valid data의 쓰임
- 모델의 과적합을 방지하기 위해 valid data를 사용합니다.
- valid data는 제공받은 train data에서 파생된 데이터로 학습된 모델을 검증하는 과정에서 사용됩니다.
- 즉, train data로 모델을 학습시키는 과정에서 valid data로 중간중간 학습된 모델을 평가를 합니다.
- valid data로 검증을 했을 때 평가지표가 좋지 않은 수치로 나타난다면 과적합을 의심해야 합니다.
- 더 정확한 검증 방식인 k-fold 교차 검증 방식이 있습니다. (이후에 정리하여 포스팅하겠습니다.)
3. 데이터 셋 나누는 흐름
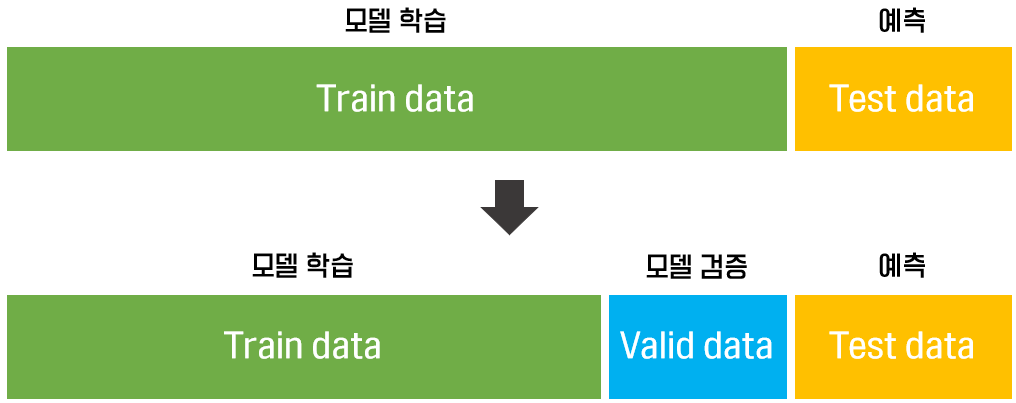
위와 같은 데이터 분리를 하게 되면 모델 검증을 통해 모델의 예측에 있어 과적합을 방지할 수 있습니다.
보통 8:2의 비율로 분리하지만 데이터 셋의 크기에 따라 7:3으로 나누기도 합니다.
train_test_split의 대표적인 파라미터
- test_size (float) : valid(test)의 크기의 비율을 지정
- shuffle (bool) : 데이터를 분리할 때 랜덤으로 분리할지의 유무
- random_state (int) : 내부적으로 사용되는 난수 값
- stratify (array) : 분리하기 이전의 클래스 비율을 분리하고 나서도 유지하기 위해 설정해야 하는 값 (종속변수의 컬럼을 넣어주면 됩니다.)
- 원본 데이터의 클래스 비율이 8:2라면 분리된 train data, valid(test) data의 클래스 비율도 8:2가 유지됩니다.
- 따라서 stratify 파라미터는 분류 문제에서만 사용 가능합니다.
Python을 이용한 코드 적용
- 보통 경진대회에서는 train data와 test data를 나눠서 주기 때문에 train_test_split은 train data를 train data/valid data로 나눌 때 사용됩니다.
from sklearn.model_selection import train_test_split
# 종속변수(target)의 컬럼을 target으로의 선언이 필요합니다.
target = train['target']
# train data를 8:2로 train data와 valid data로 분리
x_train, x_valid, y_train, y_valid = train_test_split(train, target,
test_size=0.2,
random_state=83,
shuffle=True,
stratify=target)
- 랜덤으로 데이터가 분리되었기 때문에 분리된 데이터의 인덱스는 정리해주는 것이 좋습니다.
# 인덱스 정리
# drop = False로 설정하면 정리되기 전 인덱스가 새로운 컬럼으로 생성됩니다.
x_train = x_train.reset_index(drop=True)
x_valid = x_valid.reset_index(drop=True)반응형
'ML & DL > Data Preprocessing' 카테고리의 다른 글
'ML & DL/Data Preprocessing' Related Articles
more



Comments