
코딜기
[Python/ML] 모델 평가(Model Evaluation) - 이진 분류 로그 손실(logloss) 본문
ML & DL/Model Evaluation
[Python/ML] 모델 평가(Model Evaluation) - 이진 분류 로그 손실(logloss)
코딜기 2022. 12. 22. 01:32반응형
이진 분류의 로그 손실(logloss)이란 무엇일까요?
- logloss는 분류 문제의 대표적인 평가지표이며 교차 엔트로피(cross-entropy)라 부르기도 합니다.
- 실제 값을 예측하는 확률에 로그를 취하여 부호를 반전시킨 값입니다.
- 즉, 분류 모델 자체의 잘못 분류된 수치적인 손실값(loss)을 계산합니다.
- logloss는 낮을수록 좋은 지표입니다.
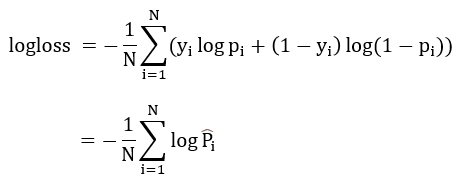

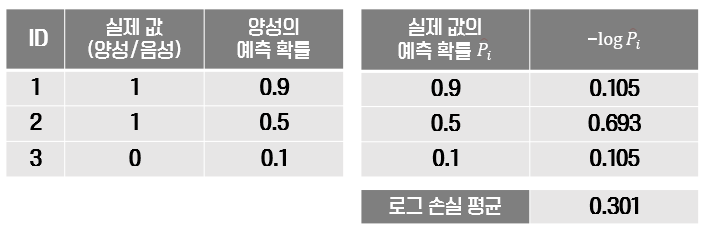
- 위 예시처럼 각 행 데이터가 양성일 확률을 낮게 예측했음에도 양성(1)일 경우나, 양성일 확률을 높게 예측했음에도 음성(0)일 경우에는 패널티가 크게 주어집니다.
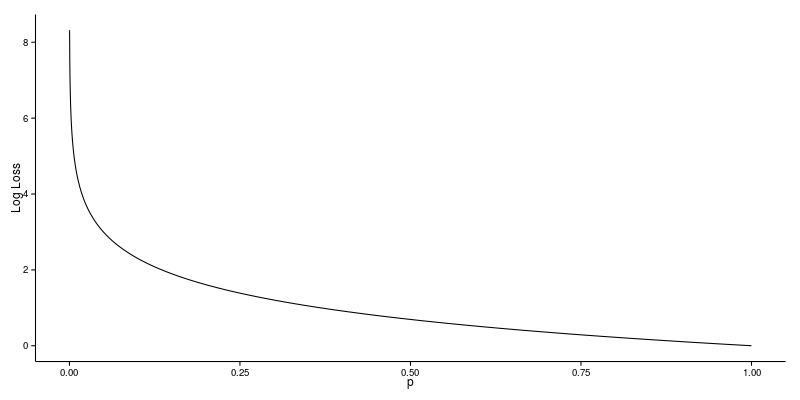
- 위 그래프처럼 예측값이 1이 될 확률을 1로 정확하게 예측할 때 로그 손실의 값은 최소가 됩니다.
Python (이진 분류)
from sklearn.metrics import log_loss
# 데이터 스플릿으로 y_valid와 모델 예측으로 y_pred_proba를 구한 후 실행
# 모델 검정이 없다면 y_true값으로 y_valid 대체
binary_logloss = log_loss(y_valid, y_pred_proba)
print(binary_logloss)- logloss를 계산하기 위해서는 확률 예측값(predict_proba)이 필요합니다. 클래스 예측값(predict)은 확률값 대신 예측된 클래스 값을 반환하기 때문에 logloss값을 계산할 수 없습니다.
- 다중 분류에 대한 logloss는 여기를 참고하시면 됩니다.
도메인에 따라 적절한 평가 지표를 선택해서 확인해야 합니다.
반응형
'ML & DL > Model Evaluation' 카테고리의 다른 글
'ML & DL/Model Evaluation' Related Articles
more




Comments